Mission-ready AI customization for defense and enterprise
Transform open-source LLMs into production-grade systems optimized for edge deployment, classified environments, and mission-critical decisions.
We fine-tune AI where others cannot deploy.
Executive Summary
Post-training is growing at a 79.8 percent CAGR through 2030, yet 95 percent of GenAI pilots fail, largely due to data quality gaps. FORGE closes that gap by delivering fine-tuning, alignment, and deployment services built for the realities of defense, enterprise, and mission-critical environments.
We combine sparse-data learning, edge optimization, and compliance-ready transparency to make open-source models production-grade. This is where performance, security, and operational constraints meet.
Post-training market through 2030
Driven by data quality and deployment gaps
Training data required for results
Detection improvement with less data
Company Positioning
577 Industries operates at the intersection of AI, robotics, and physics. That convergence lets us build post-training systems that deploy on real platforms, not just in lab environments.
- U.S. Army Project Linchpin Operationally fielded AI with mission-grade requirements.
- Department of the Navy Secure deployment in contested environments.
- U.S. Space Force Space domain analytics at scale.
- Commercial clients Rogue Fitness, Nationwide Insurance, and others.
IRIS System Proof Point
55 percent detection improvement with dramatically reduced training data, validating our sparse-data learning capability.
Why FORGE for mission-critical AI
We deliver production-grade models where security, explainability, and edge constraints define success.
Sparse-Data Expertise
Deliver high-performing models with 10x less training data to overcome data scarcity.
Edge-Optimized
Quantization and compression tuned for tactical hardware and low-power deployment.
Security-First
Air-gapped, ITAR compliant workflows with IL5/IL6 readiness.
Explainable AI
Transparent, auditable outputs for mission-critical decisions.
Customization capabilities
Fine-tuning services tailored to secure, resource-constrained, and regulated environments.
Fine-Tuning
LoRA, QLoRA, and full SFT to adapt Llama 3, Qwen, and other open models to your data and mission.
10x less data Learn more →Alignment
RLHF, DPO, and Constitutional AI to enforce safety-critical behavior and transparent decisions.
Safety-critical Learn more →Distillation
Teacher-student compression for 3 to 5x faster inference without sacrificing accuracy.
3-5x speedup Learn more →Edge Optimization
Quantization, pruning, and compression tuned to tactical hardware and limited power budgets.
Tactical hardware Learn more →Sovereign Deployment
Air-gapped, ITAR compliant pipelines with IL5/IL6 readiness and US citizen data handling.
IL5/IL6 ready Learn more →Market landscape and opportunity
FORGE is positioned between hyperscaler platforms and defense integrators, providing deep fine-tuning where secure deployment is required.
Market tiers
Underserved gaps
Emerging techniques integrated into FORGE
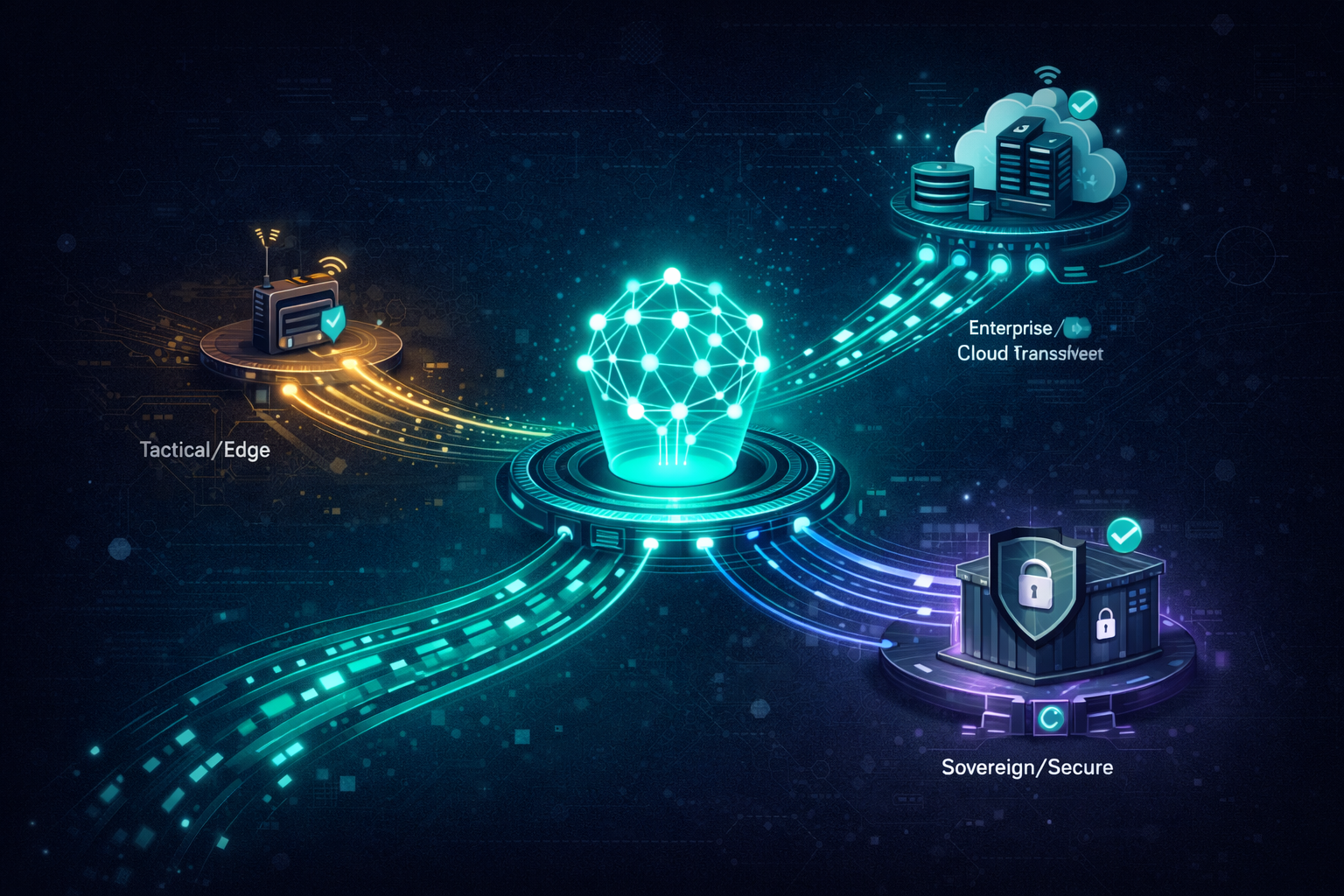
FORGE service tiers
Choose the deployment and compliance model that matches your mission requirements.
FORGE Tactical
LoRA and QLoRA tuning optimized for edge devices and tactical hardware.
- Quantization and compression
- Edge deployment ready
- Project-based delivery
FORGE Enterprise
Full SFT with managed infrastructure and multi-GPU scale.
- Managed training clusters
- Cloud or hybrid deployment
- Compute-based pricing
FORGE Sovereign
Air-gapped, ITAR-compliant environments for classified workflows.
- IL5 and IL6 readiness
- On-premises delivery
- Custom engagements
FORGE Alignment
RLHF, DPO, and Constitutional AI to lock in mission-safe behavior.
- Bias and safety testing
- Human-in-the-loop oversight
- Policy-constrained outputs
FORGE Distillation
Teacher-student compression for faster inference and lower latency.
- 3 to 5x inference speedup
- Latency optimization
- Compute-based delivery
Key features and benefits
A full post-training stack designed to move from prototype to production without friction.
Deep customization
- Fine-tune Llama 3, Qwen, and other open models on proprietary data
- Structured outputs: JSON, SQL, code, and domain formats
- Long-context training up to 100k tokens
- Domain terminology and style adaptation
Accelerated time-to-production
- Multi-GPU clusters from 8 to 512 GPU scale
- Distributed training with optimized frameworks
- Stable training for very large models
- Prototype to production in reduced timeframes
Cost efficiency and optimization
- Knowledge distillation for 3 to 5x faster inference
- Speculative decoding for latency reduction
- Token-based transparent pricing
- No idle GPU costs
Deployment and integration
- One-click deployment to production
- Secure API endpoints
- Cloud, on-premises, or edge deployment
- Enterprise-grade reliability and SLAs
- Zero data retention options for sensitive data
From data to deployment
A structured pipeline for post-training delivery and deployment.
-
01

Data Assessment & Preparation
Data assessment, dataset prep, schema design, and readiness checks for sensitive data.
-
02

Model Selection & Configuration
Select the base model and configure LoRA/QLoRA or full SFT, plus distillation and quantization targets.
-
03

Training & Alignment
Supervised training, DPO/constitutional alignment, and structured output validation with bias testing.
-
04

Evaluation & Deployment
Evaluate robustness and performance, then deploy to cloud, on-prem, or edge endpoints with integration support.
Industry applications
Post-training services for defense, enterprise, and regulated industries.
Defense and Aerospace
- Threat assessment and intelligence analysis
- Autonomous decision support for operations
- Multi-source sensor data fusion
- Military protocol and jargon understanding
Financial Services
- Proprietary risk model integration
- Fraud detection for firm-specific patterns
- Regulatory compliance and auditability
- Complex terminology support for customer service
Healthcare and Biotech
- Clinical assistants trained on hospital data
- Patient triage with local best practices
- Research paper parsing and hypothesis generation
- Drug discovery with proprietary compound libraries
Manufacturing and Infrastructure
- Predictive maintenance from sensor data
- Operations optimization for throughput
- Equipment failure prediction
- Maintenance scheduling automation
Additional Sectors
- Legal: case law research assistants
- Media: editorial style-matched generation
- Government: policy document analysis automation
Implementation timeline
A six-week launch path from service definition to optimization.
Phase 1
Service definition, content development, case study templates, FAQ, and schema markup.
Phase 2
Design system updates, component build-out, and interaction design.
Phase 3
Technical implementation, routes, structured data, and component integration.
Phase 4
Launch readiness, SEO, performance checks, and optimization.
Pricing framework
Full tier detail for budgeting and procurement planning.
| Tier | Model | Target client |
|---|---|---|
| FORGE Tactical | Project-based | SMBs, startups |
| FORGE Enterprise | Compute-based | Mid-market |
| FORGE Sovereign | Custom + project-based | Defense, government |
| FORGE Alignment | Project-based | Safety-critical industries |
| FORGE Distillation | Compute-based | Cost-sensitive deployments |
Strategic recommendations
Short-term actions to support launch momentum.
Immediate actions (next 30 days)
- Finalize service naming and positioning
- Develop detailed service descriptions and pricing
- Begin component development and integration
- Adapt IRIS and SATWATCH proof points
Medium-term actions (60-90 days)
- Develop 1-2 new case studies
- Create technical whitepapers on edge fine-tuning
- Establish cloud provider partnerships
- Engage DoD innovation units and launch campaigns
Success metrics
Targets for launch and year-one impact.
First 90 days
- Page visits: 5,000+
- Consultation requests: 25+
- Whitepaper downloads: 100+
- Time on page: over 3 minutes
- Bounce rate: under 40 percent
First year
- Qualified leads: 100+
- Proposals submitted: 25+
- Contracts closed: 5+
- Revenue: 500K+ from service line
- Defense sector clients: 3 or more
FAQ
Common questions about FORGE post-training services.
What models can you fine-tune?
We fine-tune open-source models such as Llama 3, Qwen, and other leading architectures based on mission fit.
How is pricing determined?
Pricing is based on tier selection, dataset size, compute requirements, and deployment constraints.
What about data privacy and security?
We support zero data retention and ITAR-compliant handling with US citizen data access when required.
How long does fine-tuning typically take?
Timelines depend on data readiness and model size, but most engagements move from prototype to production in weeks.
What is the difference between LoRA and full fine-tuning?
LoRA updates a small set of parameters for efficiency; full fine-tuning updates the entire model for maximum adaptation.
Can you work with classified data?
Yes. FORGE Sovereign supports air-gapped environments and IL5 or IL6 readiness.
What hardware do you use for training?
We use scalable multi-GPU clusters from 8 to 512 GPUs depending on the engagement.
How do you ensure model quality?
We run structured output validation, bias testing, and compliance checks before deployment.
What deployment options are available?
We support cloud, on-premises, and edge deployments with secure API endpoints.
Do you provide ongoing maintenance?
Yes. We offer managed updates, monitoring, and retraining options after launch.
What industries do you serve?
Defense, finance, healthcare, manufacturing, legal, media, and government agencies.
How do you handle ITAR compliance?
We use US citizen-only data handling and air-gapped systems when required.
What is the minimum dataset size needed?
Our sparse-data methods allow meaningful results with significantly smaller datasets.
Can you fine-tune for specific output formats?
Yes. We support JSON, SQL, code, and domain-specific structured outputs.
How does knowledge distillation work?
We compress a large model into a smaller one while preserving performance for faster inference.
Ready to customize your AI?
Start a FORGE engagement and move from prototype to mission-ready deployment.